The data analysis in the website logs is carried out mainly using relevant tools and there are many types of tools。
The web version can be made available by radging, the desktop version can be used by love stations or light years, and the shell can be used to analyse the log。
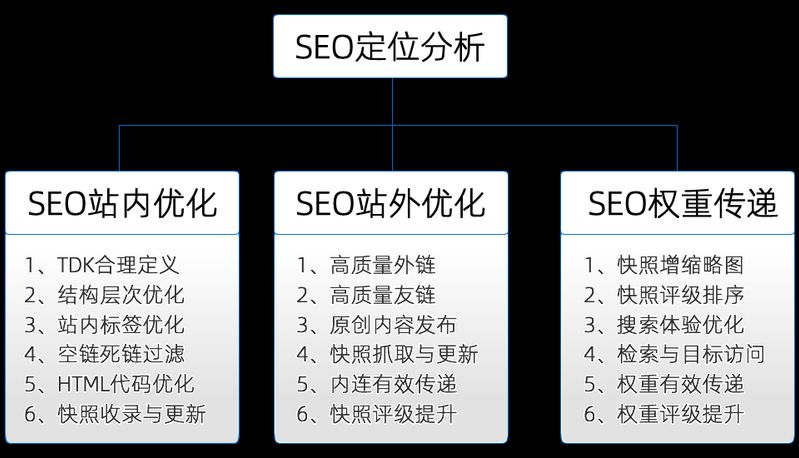
The role of the analytical log is many and can be summarized as follows:
1. Knowledge of spider capture of pages, rational distribution of web links and optimization of capture pathways
2. The flow of data on the statistical page, with corresponding policy adjustments (e. G. Data decline, analysis of causes, observation of the ab test of another page)
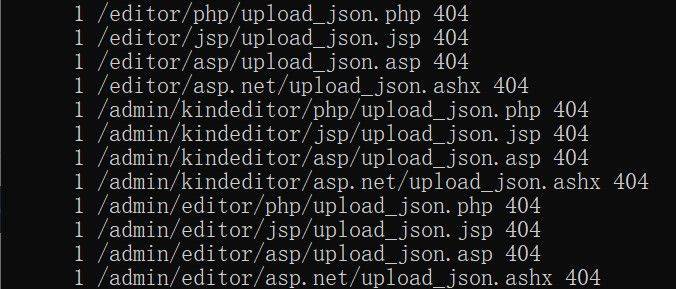
3. Extracting 404 pages and submitting them for processing
4. If the website is hacked, the log can be analyzed to see the operating records of the site and to find false 100-degree spider ips
Download the log file to the local level, where i am a pagoda, which is usually found in the www root directory。
The use of web pages is limited, and only the number of spiders captured and the return codes can be seen, as illustrated by:
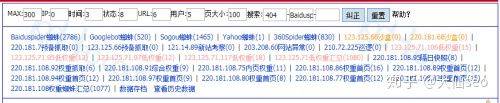
It should be clear where the number of spiders is concerned, by the way explaining the low weight ip and the weight ip shown above (the great god omitted, allegedly cope)。
Since its inception, it has been said that spiders are classified, some are specialized in capturing pictures, some are specialized in capturing videos and some are specialized in capturing content。
These ips are all called low weight ips (and i don't know where to hear them), specializing in capturing new stations or low-quality pages, during which the new station should be a type of ip of 123. 125. 71.*, with more frequency。
123. 125. 71. 95
123. 125. 71. 97
123. 125. 71. 117
123. 125. 71. 71
123. 125. 71. 106
If it's an old website, and the frequency of this ip is suddenly increasing, it's important to note that it's likely to be on the edge of k or power。
This pip shows a snapshot of the next day, meaning that the pages that he captured would be recorded the next day or that the note would be updated。
220. 181. 108. 95
These pips are called “high weight ip”, or 220. 181. 108.* pages that they have captured, which are recorded and updated very quickly。
220. 181. 108. 75
220. 181. 108. 92
220. 181. 108. 91
220. 181. 108. 86
220. 181. 108. 89
220. 182. 108. 94
220. 181. 108. 97
220. 182. 108. 80
220. 181. 108. 77
220. 181. 108. 83
All right, ip section is over。
Looking at the left, you can see a lot of code segments。
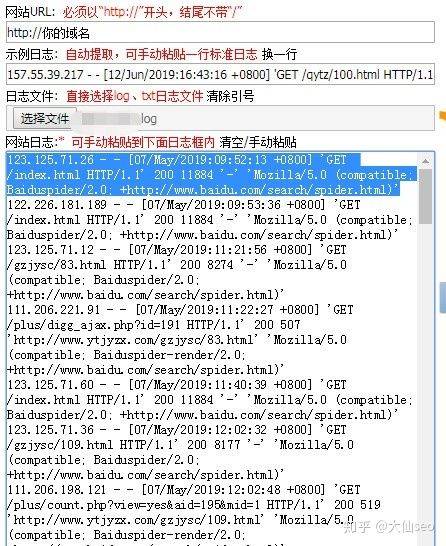
Actually, we took a complete field like this:
123. 125. 71. 12 -
07/may/2019:11:56 + 0800
'get /gzjysc/83. HTML http/1. 1'200 8274'--♪ i'm sorry ♪'mozilla/5. 0 (compatible; baiduspider/2. 0; +http://www. Baidu. Com/search/spider. HTML)♪ i'm sorry ♪
One by one, all mean。
123. 125. 71. 12: ip of the visit
07/may/2019:11:21:56 + 0800: time frame for the visit
Get /gzjysc/83. HTML: urls visited
Http/1. 1: a request agreement for a website
200: the website returns the status code
Baiduspider/2. 0; +http://www. Baidu. Com/search/spider. HTML: indicates that this is a real 100-degree spider
Ok, this is where the basic data concept is explained, and then look at what information can be obtained from the log files。
Using the light-year log analysis tool, the following information can be obtained:
Spider captures the most, followed by dog searches, and finds that there are no 360 spiders here, adding 360 spider to the settings for reanalysis。
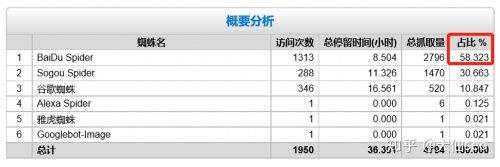
The maximum number of hits shows that the number of hits per spider is different, and it is not surprising that the maximum number of hits can be observed. Because the key words on this directory page rank best

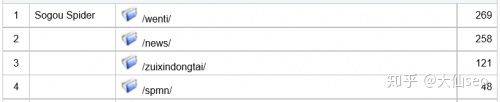
It is also possible to look at the 404 pages and place these 404 url in a txt file named silian, uploading the root directory to the 100-degree platform。

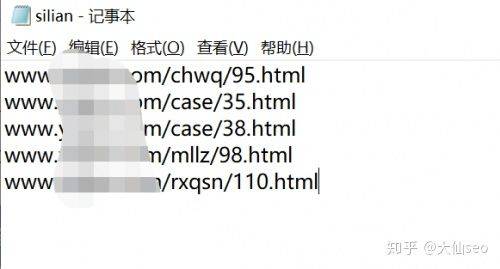
Other data can be seen for yourself
The above methodology is sufficient to analyse ordinary small business station logs, and the gold flower log tool can meet most of the needs。
This allows for the use of shell analysis of website logs for some log files that are larger and unsuited (the following is a purely x-filled version that can be omitted)。
The first is to open the log file。
Analyzing the most captured pages of spiders:
It's not a good idea'baiduspider/2. 0'awk'cause i don't knowIt's a little bit of an uniq, or a bit of a head-10
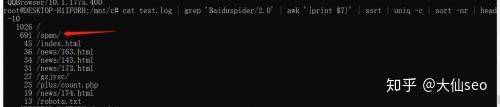
See also /spmn. This is the first page。
Find some non-200 stat url:
It's not a good idea'baiduspider/2. 0'awk'if! = "200" {print $7, $9}It's just a little bit of a "uniq" thing
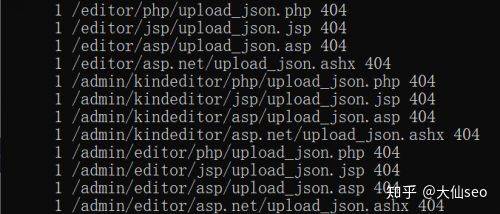
You can see the 404, 304, etc. Pages. In particular, 404 pages were identified and resolved according to the above mentioned methods。
All of a sudden, mr. Ruther said that the data themselves were useless and that it was valuable to analyse them。