
Screaming frog seo spider 13 is a powerful web-based reptile development tool, a generic tool, a web-based resource detection search tool that supports capture, analyzes all unresponsive web pages by testing their performance, analyzes web pages with virus alerts, resources for testing both the enterprise website and the search network, and facilitates the work of station chiefs. It supports practical features such as analysis of page titles and metadata, discovery of duplicate content, extraction of data, generation of xml site maps, auditing/audit re-orientation, which, for users, greatly facilitates the maintenance of the website and is an excellent and professional seo tool that is highly recommended. This brings to the user friends the screaming frog seo spider 13 deciphered downloads, with a register attached to the data package, which provides perfect access to the serial number that generates a valid registration code, thereby perfecting the registration software, removing functional limitations and allowing users unrestricted access to all free features of the software, and the users who need it to come to the download experience。
Functional feature 1, find disconnected links
Access the website immediately, find damaged links (404) and server errors. Batch export error and source url to fix or send to developers
2. Audit reorientation
Find temporary and permanent reorientation, identify redirective chains and cycles, or upload a list of web sites for audit in the context of website migration
3. Analysis of page titles and metadata
Analyse page titles and meta descriptions during the capture process and identify long, short, missing or duplicate page titles and meta descriptions in your website
4. Discovery of duplicate content
Check with md5 algorithms to find precise duplicate sites, partially duplicate page titles, instructions or headings and find lower content pages
5. Data extraction using xpath
Use css path, xpath or regex to collect any data from HTML on the web page. This could include social tags, extra titles, prices, sku or more
6. Review of robotics and directives
View by robots. Txt, mEta robots or x-robots-tag commands (e. G. "noindex" or "novollow" and canonicals and rel= "next" and rel= "prev"
7. Generate xml site maps
Quick creation of xml site maps and image xml site maps, with advanced configurations containing urls, last revision, priority and frequency changes
8. Integration with google analytics
Connect to google analyticsapi and capture user data, such as session or jump rate and number of conversions, target, trading and landing page incomescreaming frog seo spider 13 install decryption course 1 and run software installation master program, then install software based on installation wizard tips
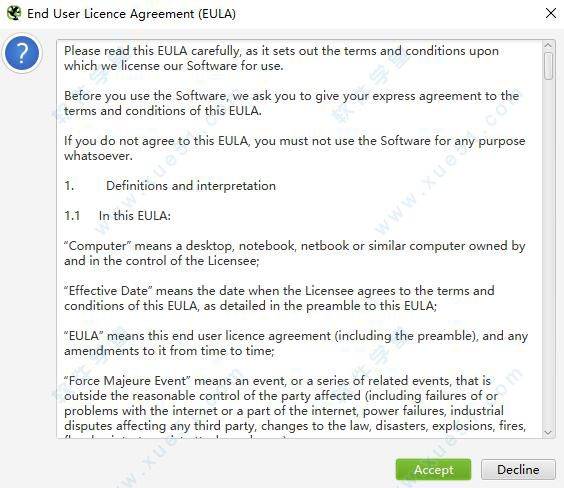
2. After successful software installation, double-click on software, read software license protocols, click on accept after reading
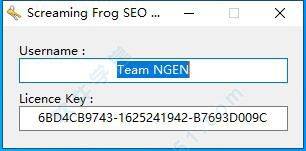
3 and then run and open the keygen. Exe register in the keygen ngen file, enter the username, and automatically acquire and generate the registration number
4. Click on enter licence under the main interface of software, copy the registration code from the previous step into the box where the software needs to fill in the active code, click to make sure the software is activated
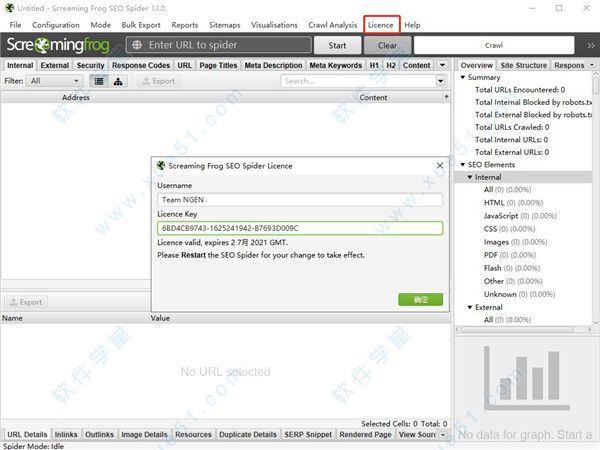
5. The following interface indicates that the software has been successfully registered
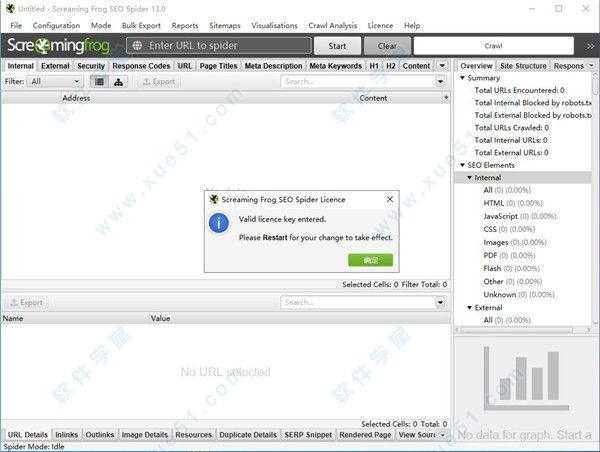
6 and so, screaming frog seo spider 13 deciphered the installation and users can use it
Use method one, crawl capture
1. General capture
Under conventional capture mode, screaming frog seo spider 13 cracks the sub-domain name you entered and treats all other sub-domains encountered by default as external links (as shown under the " external " tab). In the licence version of this software, you can adjust the configuration to select all subareas of the website. One of the most common uses of the search engine to optimize spiders is to find errors on the website, such as broken links, redirection and server errors. To better control capture, use the url structure of your website, seo spider configuration options, such as only HTML (images, css, js, etc.), exclude functionality, customize robots. Txt, include functionality or change the pattern of the search engine optimized spider, and upload a url list to capture
2. Capture a subfolder
The seo spider tool defaults to capture a subfolder path, so if you want to capture a specific subfolder on the site, you simply enter the url with the file path. By entering directly into seo spider, it will capture all urls contained in/blog/sub directory
3. Checking list of sites
You can switch to list mode, paste or upload the list of specific sites you want to grab. This is particularly useful for site migration, for example, when auditing re-direction
Ii. Organization
In a licence version of this tool, you can save the default climber configuration and save the configuration profile that can be loaded if needed
1. To save the current configuration as default, select file > configuration to save the current configuration as default
To save the profile so that it can be loaded in the future, click save file > and adjust the filename (preferably descriptive)
3. To load the profile, click " file > load " and then select your profile or " file > load recent " to select from the nearest list
4. To reset to the original default configuration, select file > configuration > clear default configuration
Exports
The export function of the top window segment works with your current view in the top window. So if you use the filter and click export, only the data contained in the filter option is exported
There are three main methods of data export:
Exporting top tier window data: just click on the export button in the top left corner to export data from the top layer window tab
Export lower window data (url information, links, output links, image information): to export these data, just right-click the url in the top window to export the data, and then click url information, link, output link, or photo information under export
3. Batch export: under the top menu, allow batch export of data. You can pass "all in l"Inks 'options export all examples of links that are found in the capture. They can also export all links to urls with a specified status code (e. G., 2xx, 3xx, 4xx or 5xx response). For example, the selection of " client error 4xx " in the link will export all links to all error pages (e. G., 404 error pages). You can also export all images instead of text, all images missing alternative text and all anchor text
Strength point 1, batch export error and source url to fix or send to developers
2. Identification of precise duplicate web sites, partially duplicate page titles, descriptions or headings
3. Collect any data from HTML on the website using css path, xpath or regex
4 through advanced configurations with urls, previous changes, priority and frequency changes
Connect to google analyticsapi and capture user data
6. Analysis of page titles and metadata, review of meta-robots and commands
7. Allows you to save the web, open the configuration options for spiders and custom source searches



