
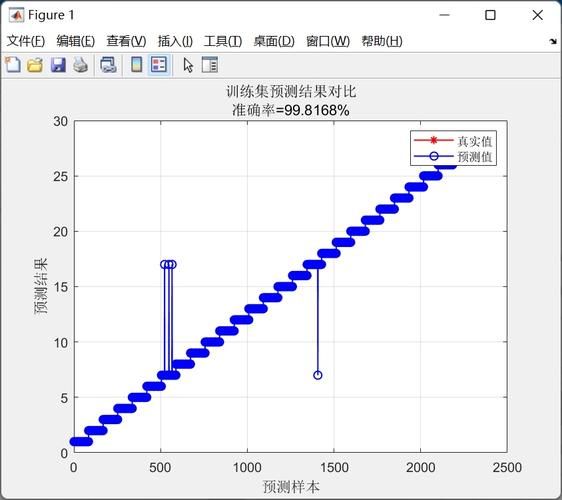
The support vector machine, svm is a classic and powerful monitoring learning algorithm that is widely applied to classification and regression missions and has excellent performance in the areas of image recognition, text classification and bioinformatics. The project, with the "handwritten digital recognition" as its core application scenario, systematically achieved the full manual digital classification process based on svm: loading and pre-processing from the mnist data set, image characterization and standardization, svm model construction and training, over-parametric adjustments (e. G., c, gamma, kernel type), cross-validation assessment, and eventually classification performance visualization and error analysis. This practice not only fully covers the critical aspects of mechanical learning engineering landings, but also provides more insight into the unique strengths and inner mechanisms of svm in high-dimensional and thin image space. The core challenges of handwritten digital recognition, which is the baseline task in the area of model recognition and computer visualization, lie in the fact that the same number displays significant intra-class differences under different writing styles, tilt angles, roughness, pen styles and image noise, while significant inter-category similarities exist between different numbers (e. G., “1” and “7”, “3” and “8”). The mnist data set, which is the gold standard for the mission, contains 60,000 training images and 10,000 test images with a greyscale of 28 x 28 pixels each for 10 categories (0-9). In this mission, svm does not deal directly with the original pixel matrix, but stretches each image to a 784-dimensional characterization vector (28 x 28 = 784) and then maps it through nuclear techniques (kernel trick) to a high-dimensional or even unlimited-dimensional characterization space in which the optimal separation super-platform — that is, to maximize the decision-making boundaries between categories (margin). This principle of “maximum spacing” gives svm a strong transversal capability and rarity to abnormal values, especially for small samples, high-dimensional, non-linear scenarios. At the characterization engineering level, the project involves critical pre-processing operations: asymmetric homogenization (in pixels zoom), de-equivalization, downscaling (optional) of the main constituents (pca) to mitigate “dimensional disasters” and accelerate training; and comparing the effects of different nuclear functions - - linear applies to near linear subdivisions and is calculated to be efficient but limited in expression; polynuclears and sigmoids are less used for image missions; and the altruistic nuclear (rbf, or rbf kernel) becomes the mainstream choice on mnist with its unlimited mapping capacity and smoothness, with its performance highly dependent on two super-parameters: regularize parameter c (control of the trade-off between penalties for misclassification and spacing width) and nuclear coefficient gamma (to determine the extent of impact of individual training samples). Therefore, the alignment of parameters is a central manifestation of the technical depth of the project: using a grid search (gridsearchcv) combined with a 50-percent or 10-percent cross-validation, in c∈ {0. 1, 1, 10, 100}, gamma∈ {0. 001, 0. 01, 0. 1) etc., the system seeks excellence and diagnoses/inconsistences with the learning curve (learningcurve) through validation of the curve. In addition, assessment tools such as scikit-learn assessment report, confusion matrix, accuracy score, can quantify accuracy, recall rate, f1-score and confusion between categories, thus locating the easily confused numbers (e. G. “4” and “9”) to guide subsequent feature enhancement or integration strategies. This project also implies the technological evolution logic of ocr: svm, the core taxonomy of traditional machines studying the ocr flow line, is often used in conjunction with manual design features such as hog (direction gradient histogram) and lbp (local binary model), which, although greatly exceeded by in-depth learning (e. G. Cnn, transformer), are highly interpretative, have low demand for training resources and high stability under small data, making it irreplaceable in embedded equipment, marginal computing, teaching demonstrations and algorithm studies. In summary, the project is not only a practical example of svm algorithms, but also a complete machine learning loop that runs through data pre-processing, model selection, over-input optimization, assessment of diagnostics and analysis of results, which provides an in-depth interpretation of the engineering philosophy of “identity decision caps, algorithms determine floors” and provides a solid basis for understanding the underlying logic of modern ai systems。



