A more based change is taking place at the bottom of the math and data when the big model is sweeping through all walks of life。
18 january, fifth oceanbIt's over. Previously, the competition had been incorporated into the national computer system capability competition for university students in 2023 as a category a competition identified by the ministry of education. The focus of the education system on talent development has once again highlighted the centrality of databases in the ai era。
According to the information received, the event attracted 1,223 teams and 2,620 students from the national higher education institutions, who faced two tasks in the finals: first, optimizing the hybrid search performance of “full text search + structured filter” and, second, building a traceable multimodular rag system based on the same database core。
The above-mentioned topics address the real bottlenecks in the current ai-landing industry: smarter models, lacking high-quality, efficient and manageable data support, are like the skyscrapers。
And the wind of the competition reveals a trend: ai is not an isolated technological revolution, but a systematic re-engineering. In the phase of accelerating change in ai and further reshaping the productivity of industries, basic software, instead of being flooded, is moving to an unprecedentedly critical location。
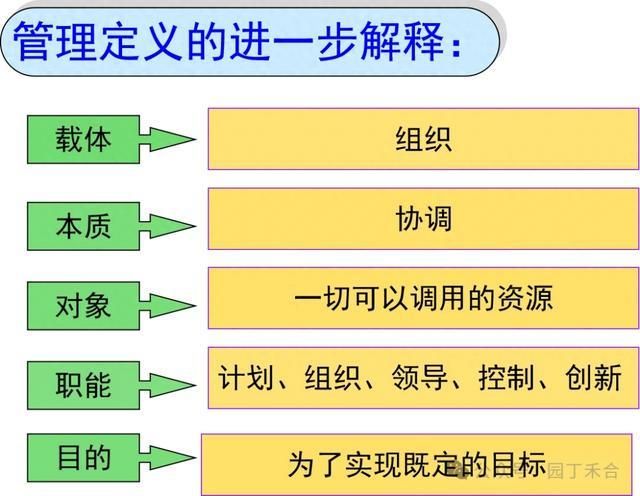
The hotter ai, the more critical the database is
In traditional perceptions, databases are like a digital warehouse to ensure the accuracy, consistency and durability of data, with the core functions of “recording” and “keeping”. But the needs of the ai era are much more than that。
In 2020, data were defined as the fifth largest factor of production for the first time alongside land, labour, capital and technology, marking a move beyond technology to economics and sociology。
This shift reveals the contradiction of the ai era: the gap between large model capabilities and the demand for applications to land。
In theory, large models understand, generate and handle complex tasks. In practice, however, enterprises face specific problems: how to quickly find relevant data, how to ensure the timeliness of information, and how to control the cost of reasoning。
When an enterprise issues a “checkout of the past seven days from a vip user with a “failure to pay” list” such instructions require not just simple data queries, but a real-time “drive” process that integrates semantic understanding, keyword matching, filtering of conditions。
This means that the database will affect response time, the accuracy of answers, and the probability of decision-making, thereby affecting the efficiency, quality and credibility of ai's access to information. As a result, the database must evolve from a passive storage carrier to an active participant in and entry to the ai reasoning chain as it accelerates its spread。
When data become a key driver of large models, managing and stimulating databases of data value, naturally they are also upgraded from back-office tools to core engines of production systems. The hotter ai, the greater the demand for real-time processing of high-quality data, and the greater the importance of databases as a bottom-up platform。
Ai loading reshaping database technical architecture
The critical upgrading of the database is directly reflected in its adaptation and support to the emerging ai load. Like this oceanbThis industry's demand is also reflected in the fact that the "mixed search performance optimization" and "retroactive multimodular rag system development" competitions are final themes。
First, “mixed search” becomes a high frequency requirement. Pure vector searches tend to be unwieldy when dealing with complex and precise structural conditions, while traditional databases have short boards at the level of semantic understanding. Future mainstream ai applications are bound to be hybrid models that simultaneously process multi-modular queries such as text, vector, relationship data, etc。
This technical innovation of the load-back database has prompted it to regroup the search, vector, transactional and so forth capabilities at the bottom, rather than simply stacking multiple stand-alone systems, thus achieving a leap forward while simplifying the architecture。
Second, “retroactivity” becomes a hard indicator for corporate-level ai. An ai-generated answer that does not indicate the source is hardly available in a serious business scene. In particular, in high-risk situations such as finance and health care, ai's decision-making process must be transparent and verifiable. The database therefore needs to build this capability internally to ensure that every smart question and answer is documented。
This requires the database not only to be able to quickly retrieve information, but also to accurately manage the version, source and context of information, providing a credible basis for ai output。
Ai load is driving the database from a closed data container to an open, manageable, auditable smart data platform。
The breakthrough of the ai era: from "able" to "good"
Changes in technology demand often lead to a reshaping of market patterns。
In the area of traditional databases, barriers created by long-term ecological accumulation exist between late and leading players. However, the new demand generated by ai, such as the extreme demand for hybrid search capabilities and the natural demand for the integrated management of multi-mode data, has to some extent created new starters。
This may provide potential overload opportunities for the chinese database。
The key to a database break-up lies in the ability to leapfrog from meeting the need for “serviceability” to providing “good use”. This requires that the database products not only operate in a stable manner, but also have a profound understanding of the characteristics of the ai workflow and create a combined advantage in performance, usability, cost and functional integration。
Professor at the faculty of data and director of the board of experts on the ccf database at the university of huatungIt was also mentioned that the large model was data-driven. This means that those who manage, cleanse and supply data more efficiently can take a more advantageous place in the ai ecology。
China has a wealth of applications and vast data resources, which offer unique advantages for the development of database technology. Basic software, such as databases, is therefore one of the key subdivisions in which china is likely to have a faster global impact。
“brain of talent” beyond hot spots
The evolution of technology depends on talent. Behind the vigil of the ai era is a desire for development talent that can sink to understand the system, optimize the inner core and weigh the reliability and performance of engineering。
Through the database-related events, it can also be observed that in the future there will be a shift in the structure of talent from “tool-enabled” applications to “system-enabled” creative talent, which will require a combination of system bottom and ai engineering capabilities。
Like oceanbThe growth paths designed for the players at the case database competition — from basic core work in the database to hard-core optimization and ai application development based on more complex seekdb in the finals — show that industrial talent development focuses on system capabilities, engineering thinking and long-termism. Young developers need to understand that, under the hot surface of ai applications, the robust and efficient base will directly determine the upper limit of the application experience。
The flood of ai technology does not dilute the value of basic software. At present, ai technology ecology is moving from a “big model centre theory” to a “two data and systems centre”. The database, an area of technology that has evolved over decades, was given a new mission in the ai era — no longer as a hero behind the scenes, but as a core pillar of the intellectual revolution, alongside algorithms and algorithms。