
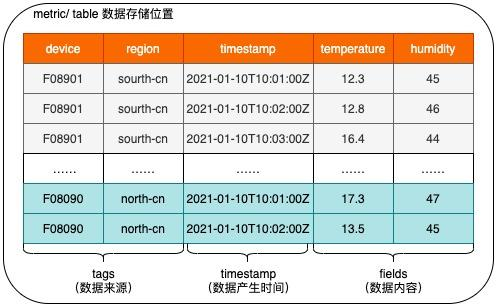
The area of material networking has recently become quite hot, with the internet and traditional companies competing for a network of layouts. The prime time series database, which is the repository of data in the domain of the internet, is also increasingly gaining visibility, and as early as july 2016, the 100-degree cloud released the country's first multi-tenant distributed time series database product, tddb, on its skycraft network platform. The reference to time series data in the preceding section is a more read-and-read-out scenario that addresses time series databases and data storage, and data queries and aggregation calculations are also one of the essential features of time series databases. How to support the aggregation of query clusters of hundreds of millions of data in seconds becomes a challenge for time series database products。
This will be done from the point of view of time-series database queries and aggregation calculations, followed by an in-depth analysis of how to solve the time-series data queries。
1. Time series data queries
The user search landscape for time series data varies, and the search for time series data in general can be divided into two types: the query for original data and the query for aggregation of time series data. The former is a query for historical high-precision time series data, the result of which is too thin and does not facilitate the detection of regularity and trend; nor is it suitable for presenting metadata to users, mainly for large data analysis. The latter is mainly used to analyse data, such as the ui tool, such as dashboard, which displays data analysis results using aggregate queries. This paper focuses on the optimization of aggregate analysis queries。
2. Optimization of time series data queries
As can be seen previously, the storage of time series data consists mainly of single machines and distributed storage. The time series data are stored in a single machine or distributed environment according to the fractional rules (usually using metric+tags+timescales). When you search all data fractions according to the query condition, all fractions are combined by a time stamp to form the original data result, and when the query condition includes the polymeric operation, the data are aggregated according to the sample window and the result is returned。
The calculation of the delay in the data aggregation operation query can be described in a rough way as follows:
Aggregation operations querying for data fractions + aggregation operations + data return
Figure 1 time series data query process
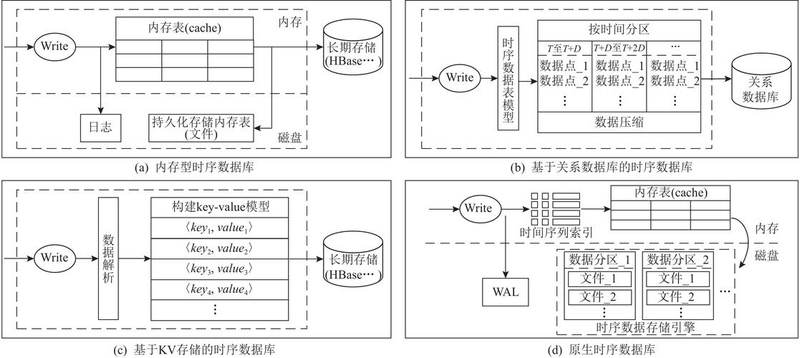
Queries for polymeric operations can be optimized in two directions: distributed aggregation queries and pre-processing of data. Distributional aggregation queries improve performance by combining multiple nodes with parallel queries and calculations, reducing the time spent on fractional queries and aggregation calculations, and ensuring the return of time series data analysis results in seconds. Data preprocessing, on the other hand, is the idea of space-for-time, precalculating the data according to the query rules, and directly returning a small amount of aggregate results when searching to ensure that lower queries are delayed. The time-series database can be optimized in two ways, followed by an in-depth analysis of pre-processing data。
3. Pre-processing of time series data queries
Pre-processing of time series data can be divided into two types based on real-time: batch processing and flow processing。
I batch processing
Batch processing is the use of pull to query the original time-series data, pre-assembly the results of data acquisition to be written in the time-series database, and to return the pre-processed data results directly to the pre-processed data results when the aggregation query is made. The time series database periodically rotates the interrogation rules, creates pre-processing tasks based on a sample window, and tasks create multiple task queues based on the rule information. The tasks in the queue are carried out in the order in which they are carried out, and the multitasking queue ensures the sharing of resources between the multiple tenants。
Figure 2 processes
Pre-treatment tasks are carried out mainly in two types of environments: a single machine environment and a distributed environment。
Single environment: the mission movement module is relatively simple in logic, and the movement module is used to obtain unexecuted pre-processing tasks from within the queue in order that the tasks are submitted to the line pool for execution, either through information within the process or by rotating multiple task queues。
Distributive environment: multiple computing nodes share task queues, pre-processing tasks are looted, linear extensions of computing nodes are supported, and distributed environments can contain multiple realizations。
A) message queue: the time-series database rotates the pre-processing rules, adding task messages to the message queue when creating a pre-procession task, setting up message groups, using the same grouping for the same rule. Computes the node consumption task message, executes the message sequence in the group, and sends the message outside the group。
(b) harmonized hash approach: multiple calculation nodes form a consistent hash ring by means of a consistent hash algorithm, and pre-processing missions submit the same task line to the same calculation node according to a syllable algorithm (using rule-based information) to ensure the sequence of tasks。
(c) movement control module approach: the movement of task queues is carried out in a unified manner by the movement control module, and the same rules tasks are submitted to the same computing module to ensure their sequence。
Isophisticate
Fluid processing frames can also support the aggregation of data streams, unlike batch processing, where time series data need to be routed to flow processing frames such as spark, flInk, etc., when the data time stamp reaches the sample window, it is calculated in real time in the memory and written in the time series database。
Figure 3 fluent pre-treatment
Fluctuation processes are distributed memory calculations, and the same sample window data need to be aggregated in the same computing unit, so the same data flow needs to be mapd to the same computing unit, and data streaming is the core issue to be addressed in the current processing。
(a) centralized movement control: the movement control module harmonizes the movement data flow and uses the same data stream for the same calculation module。
(b) consistency-hash approach: the correct calculation of memory data is ensured by using fractions (using rule information) to map the same pre-processing rule data to the same computing unit。
Batch processing has the advantage of supporting the processing of historical time series data and achieving simplicity. Batch processing, however, has a large amount of query data and a non-real-time disadvantage. The advantage of current processing is that the data are calculated in real time without reference to raw data. However, flow processing requires special processing of written historical data and processing of computing units that collapse in computing. Batch processing and process processing have advantages and disadvantages, and the usual time series database requires pre-processing of data in two ways。
4. True examples
Lopentsdb time series database
The latest version of opentsdb currently does not support pre-processing of data, but it can be seen in the roadmap of opentsdb that new apis are intended to be used in opentsdb2. 4 and subsequent versions, mainly in batch and current processing。
Batch processing: based on the sample window, a regular query of the original data is used to aggregate the calculations and store the results。
Fluid treatment: combining spark, flInk flow-processing framework to calculate time series data flows in real time。
Opentsdb expects pre-processing to provide a more efficient search experience for users, while addressing the problem of system collapse when large data queries are calculated。
Linfluxdb time series database
Influxdb for cq(co)Function, cq calculates by regular pull raw time series data and stores the results in the internal special metric. Users pre-process data by creating cqs, the main cq parameters of influxdb include the name of the polymer function, the name of the storage metric, the name of the query measure, the sampling time window and the label index。
Select into from group by time()
Concluding remarks
Use pre-processing to effectively reduce the instant search pressure on the system by searching for sample aggregate functions, and to allow data to calculate multiple queries, while also effectively reducing the delay in searching and improving user experience. The 100-degree sky series database platform also introduced pre-processing in late 2016 to meet the viewable need for high frequency and low time delay for polymer queries。
However, the time series database continues to face performance, high delays and will be analysed in depth in subsequent articles for a large volume of original data queries。
( )



