The search engine then parses the web page and extracts the main content of the page and the links to other pages contained therein. In order to speed up the response to user queries, the content of the web page is maintained through the efficient search data structure, the “reverse index”, and links between web pages are maintained. Because the relative importance of the page can be judged through a “link analysis”, it is very helpful to provide users with accurate search results。
At the same time, cloud storage and cloud computing platforms are used as the basis for search engines and related applications because of the huge amount of data information available. The above information on how search engines access and store mass web pages does not require real-time calculations and is therefore seen as a back-office computing system for search engines。
Search engine front desk computing system
The most important purpose of the search engine is to provide users with accurate and comprehensive search results, and how to respond to user queries and provide accurate results in real time constitutes the search engine front desk computing system。
When the search engine receives the user's query word, it first analyses the query word in the hope that the true search intent of the user can be correctly derived by combining the query word with the user's information. Find first in the cache, where the search results of different queries are stored with different intents, and if information to meet user needs is found in the cache, return directly to the user, i. E. Save resources and speed up the response. Call the web sorter module if the cache does not exist。
“webline sorting” calculates in real time which pages meet the information needs of users based on their queries, and sorts out the search results. The two most important factors in the ranking of web pages are: the similarity of content (which pages and user queries are relevant) and the importance of web pages (which are of good quality or relative importance and are obtained through a link analysis). The web pages are then sorted as search results for user queries。
At the same time, the “anti-deception” module of the search engine has identified, inter alia, ways of raising the search ranking of web pages to a level that is not commensurate with the quality of their web pages, which can seriously affect the search experience. There is also a phenomenon of successful new internet companies blocking search engines’ reptiles, such as facebook’s google shield, and domestic treasure-hunting’s 100-degree shield, mainly as a competition strategy between commercial companies, which can be seen as vertical and generic。
(iii) simple technical analysis of search engines
According to technical principles, search engines can be divided into three categories:
1. Full text search engine (full text search engineering)
Foreign representatives include google, yahoo, altavista, teoma, etc., and in the country are 100 degrees, north great skynet, etc. They are all databases created to extract information from each site from the internet (predominantly in the text of the webpage), to retrieve records that match the user's search conditions, and to return the results to the user in a certain order。
2. Directory search engine (search index)
It is not a true search engine in the strict sense, but a list of web links by catalogue, although it has a search function. Users are well placed to find the information they need without a keyword search and only by cataloguing, the most representative being yahoo yahoo. In the country, fox searches, internet access, new waves, hao123 etc. All fall into this category。
The directory interface is typically hierarchical, with users accessing from the basic large entry level down until the desired content is found and users can search for keywords through the search functionality provided in the directory. As a result of the manual classification, the results of the search are more accurate than those of the robot search, but the limitations are also evident。
3. Meta-search engine (m)I don't know
When responding to a user query request, it conducts searches on multiple other engines and does not carry out www itself or its own index database. When a user queryes a keyword, it converts a query request to the command form of another search engine, submits it separately to another search engine, then summarizes the results returned by the search engine and returns to the user browser. The famous search engine for stars is a chinese capital search engine。
The search engine usually consists of four components: searcher, indexer, searcher and user interface。
Based on the characteristics of the chinese word, the chinese search engine has to have a special chinese information processing module to complete the word-processing, code-conversion and full-angle processing of the chinese document, due to the number of characters in chinese, the complexity of the code, the difficulty of the chinese word-speeching。
At the same time, in the 100-degree job, you might see that its core departments include web search, vertical search, etc. So what is a vertical search? Here's a simple addition。
Vertical search engine
It is also called a thematic search engine or a thematic search engine. It consolidates specific types of information in the web library, focusing only on one area or region, which, after storage and indexing, allows users to retrieve information that only covers that part. The biggest difference between a vertical search engine and a general search engine is that a general search engine is for all users, whereas a vertical search engine is for users in a given field. For example, hotels, roads, public transports, shop information, etc., the search engine for life is extremely satisfying the travel and tourism of users。
Core techniques for traditional search engines often include terminologies, web spiders, indexing techniques and word frequency indices。
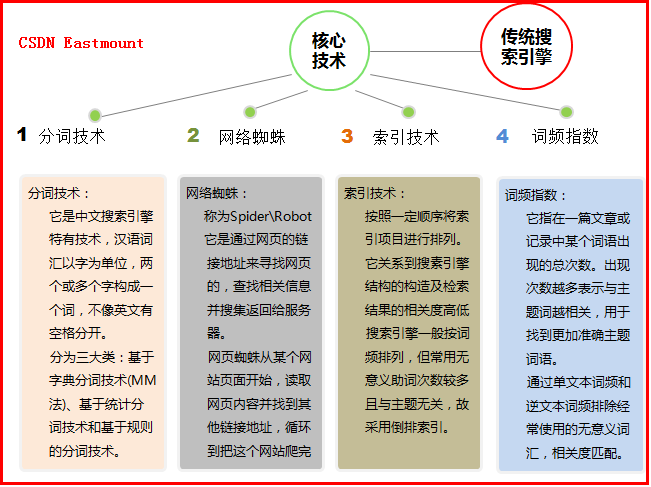
With the emergence of intelligent search engines, like grunt. Its core techniques include automatic reasoning techniques, in-house knowledge systems, expert systems, etc., which focus more on integration with other sciences, individualized search, and higher intelligence. But i am not here to describe it, because knowledge mapping or knowledge computing engines are considered the next generation search engine, and i would like to share this part of the basic knowledge. In other words, it is also a very smart, user-centred search technology that needs to understand user needs。