Kmp and bf algorithms
Questions commonly used to match strings, such as abcdabcefgh matching abce
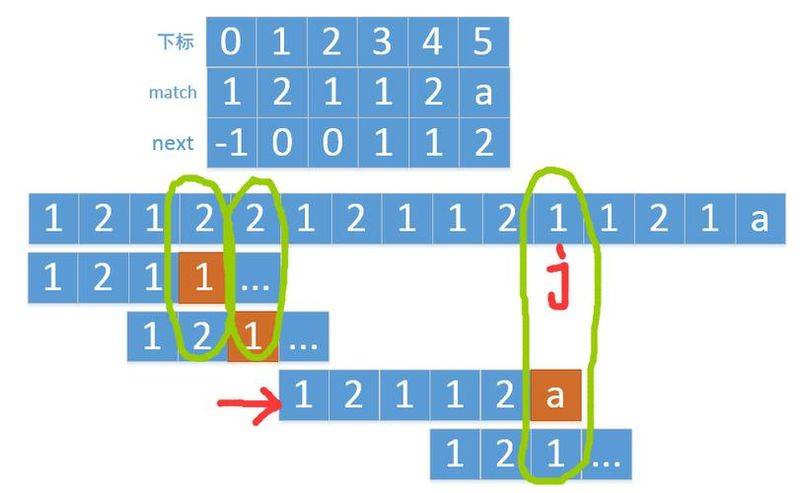
Bf algorithm
Encyclopedia: the bf algorithm, the bruteforce algorithm, is the normal model matching algorithm bf algorithm idea to match the first character of the target string with the first character of the pattern string t, and, if equivalent, continue to compare the second character of s with the second character of t; if not, compare the second character of s with the first character of t, then compare it sequentially with the first character of t, until the final matching results are obtained. The bf algorithm is a force algorithm。
In short, the cycle of violence
1. First round (match, i = 0, j = 0)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
second time (match, i=1,j=1)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
third time (match, i=2,j=2)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
fourth (unmatched, original string moved back one, i = 3, j = 3)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
fifth time (unmatched, original string moved back one, i=1,j=0)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
sixth time (unmatched, original string moved back one, i=2,j=0)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
7. Seventh (unmatched, original string moved back one, i=3,j=0)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
eighth time (match, continue to compare later, i=4,j=0)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
ninth (matching, continuing later comparison, i = 5, j = 1)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
tenth (matching, continuing later comparison, i = 6, j = 2)
zenium
original string: a b c d a b c f g h
match string: a b c e
zenium
11. Eleventh time (matching, all matching strings completed, all matching, returns, i=7, j=3)
zenium
original string: a b c d a b c f g h
match string: a b c e
zeniumBf algorithms are easy to understand, but they're not very good because a lot of useless duplicates, such as those found in step 4 above, are useless duplicates
Code:
: = "ababcababa"
ts: = "ababa"
sstrlen: =len(str)
tslen: =len(ts)
i, j: = 0,0
♪ for i ♪Kmp algorithm
Encyclopedia: the kmp algorithm is an improved string matching algorithm proposed by d. E. Knuth, j. H. Morris and v. R. Pratt and is therefore called the knut-maurice-pratt algorithm. The core of the kmp algorithm is to minimize the number of matches between the mode string and the main string for fast match purposes, using information that matches the failure. This is achieved through a next() function, which itself contains local matching information for mode string. Time complexity of kmp algorithm o(m+n)
Let's get a white version first
Example: found substring "abababsa" from the main string "abababsa"
First steps
zenium
main string: a b b b b b s
subscript: 0 1 2 3 4 5 6 7 8 9
substring: a b b b b s a
zenium
2. Second step (the process of comparison was omitted, and two different locations were found for lower mark 6)
zenium
main string: a b b b b b s
subscript: 0 1 2 3 4 5 6 7 8 9
substring: a b b b b s a
zenium
3. Third step (same mark 2 ~5 found for the main string and 0 ~3 for the substring)
zenium
main string: a b b b b b s
subscript: 0 1 2 3 4 5 6 7 8 9
substring: a b b b b s a
zenium
and then we keep comparing...Why are you moving like this?
From step two
Zenium
main string: a b b b b b s
subscript: 0 1 2 3 4 5 6 7 8 9
substring: a b b b b s a
zeniumThe main and substrings are the same as the ones before the sixth mark
And the intersection of prefixes (continuous strings starting with the opening letter and not equal to their own) and suffixes (continuous strings ending with the end letter and not equal to their own) is bab
Prefix for substring: {a, ab, aba, abb, ababa}
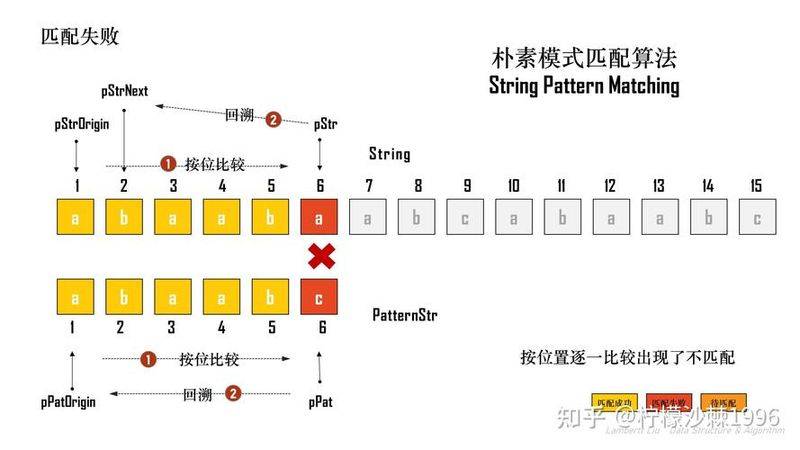
Suffix of substrings:
The two of them have an intersection
The length of the longest element in the intersection is also known as pmt, and the length of the result is four
Why the longest? Because the longest match of description is higher
Because the primary string is the same as the substring before the lower mark 6
So it can be understood as
The suffix of the main string (before mark 6) is the same as the prefix of the substring (before mark 6) (first four)!
So, step three
At this time keep the main string's comparison subscript unaltered and move the substring's substring's subscript to 4 and then start the comparison
Zenium
main string: a b b b b b s
subscript: 0 1 2 3 4 5 6 7 8 9
substring: a b b b b s a
zenium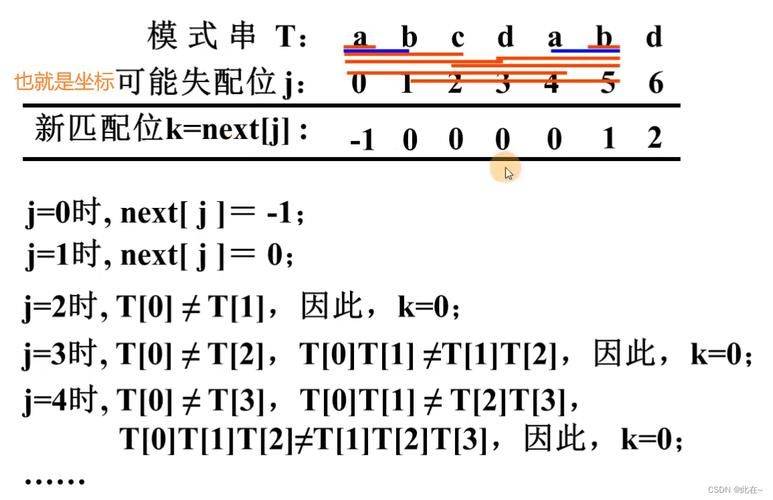
So the question is, how does this pmt code...
J i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0
t[j]≠t[j]i+next[i]=0
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0 1
t[j]=t[j]i+j+next[i]=1
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0,012
t[j]=t[j] i+j+xt[i]=j +1
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0 1 2 3
t[j]=t[j] i+j+next[i]=j+1
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0 1 2 3 4
t[j]=t[j] i+j+next[i]=j+1
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0 1 2 3 4 0
t[j]≠t[j] i++j=0 next[i]=0
j i
string: a b b b b s a
serial subscript: 0 1 2 3 4 5 6 7
next: 0 1 2 3 4 0
t[j]≠t[j]j =0
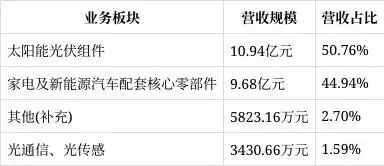
other organiserProcess is i to j to compare. If again, array values are the previous values +1, i and j move backwards, if not the same, j to 0, i continue to move backwards
Usually, for easy calculation, move the whole array to one right and set the first to one. Go on
So, next, it's {100, 1, 2, 4}
According to the above example, when it's marked down to six, the main string is different from the substring!
The value of pmt in the next array is 4
So the next comparison is the position of the main string i and the position of the substring 4!
Code:
Stra: = "abababca"
ts: = "abababca"
next: = getnext(ts)
next = next
fmt. Println(next)
sstrlen: =len(str)
tslen: =len(ts)
i, j: = 0,0
♪ for i ♪