In the last article, we talked about the word2vec model based on hierarchical softmax, and here we look at another way to solve the word2vec model: negative sampling。
1. Shortcomings and improvements of hierarchical softmax
Before talking about the word2vec model based on negative sampling, let's look at the shortcomings of hierarchical softmax. Indeed, the use of hoffman trees instead of traditional neural networks can increase the efficiency of model training. But if the central word in our training samplew is a very remote word, it has to go down in the hoffman tree for a long time. Can't you make the model simpler without a homman tree like this
Negative sampling is the way to solve the word2vec model, which abandons the hoffman tree and uses the negative sampling method to solve it. Let's look at negative sampling's solution。
2. Summary of models based on negative sampling
Since its name is negative sampling, sampling is certainly used. There are many methods of sampling, such as the famous mcmc. The negative sampling here is not as complicated as the mcmc。
For example, we have a training sample, the central word is w, and there are 2c words in the surrounding contextNtext(w)\). Because of this central word, it does and coNtext(w) exists, so it is a real case. By sampling negative sampling, we get neg and w different central words. (w i, i=1, 2, .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Ntext(w)\ and (w i\) constitute a negative example of neg that does not exist. Using this formal and neg negative example, we go back to the binary logic and get a negative sample of model parameters corresponding to each word \\(w i\) (\theta {) and the word vector of each word。
As can be seen from the description above, the negative sampling, because of the lack of hoffmann tree, can train the model every time it takes a negative example by sampling a different neg central word, so the whole process is simpler than hierarchical softmax。
But two questions still need to be understood:
1) what if a binary logical regression takes place through a positive and neg negative
2) how to conduct negative sampling
We'll discuss question 1 in section iii, and question 2 in section iv.
3. Model gradient based on negative sampling


4. Negative sampling method
Now let's see how we do negative sampling and get a neg negative. The word2vec sampling method is not complex, and if the vocabulary is v, then we split a segment of 1 into v, one word for each corresponding vocabulary. Of course, the length of the line is different for each word, the length of the line for the high-frequency word and the length for the low-frequency word. The length of the line in each wordw is determined by the following pattern:

Before we sample, we divide this line, which is 1 length, into an m equivalent, here in m>v, which ensures that each word corresponds to the line, into the corresponding piece. And each one of the ms falls on the line of a word. When we sample, we just have to sample the neg position from the m position, and the word that goes to each location is our negative。
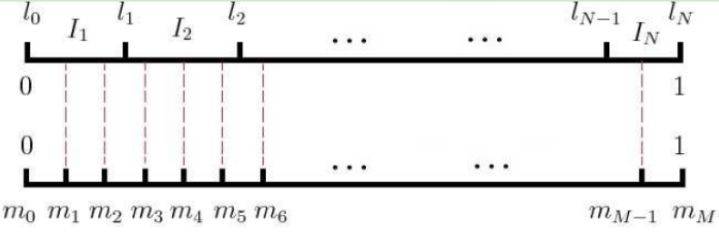
In word2vec, m takes the default value \\(10^8)。
5. Cbow model based on negative sampling
With the above-mentioned negative sampling negative sampling method and the logical regression solver model parameter, we can sum up the cbow model algorithm process based on negative sampling. The gradient iterative process uses random gradients to increase:
Input: text training sample based on cbow, term vector dimensions mccunt, cbow context size 2c, steps long, negative sample numbers neg
Output: model parameters for each word in the vocabulary \\ (θ), all word vectors \\ (x w\)
1. Random initialization of all model parameters, all word vectorsw
For each training sample \\(co)Ntext (w 0), w 0), negative sampling of neg central words \ (w i, i=1,2, ... Eg\)
3. An iterative process of gradients for each sample of the training concentration ((co)Ntext (w 0), w 0, w 1, ... W {neg}\) does the following:

6. Skip-gram model based on negative sampling
With the foundation of the previous section cbow and the basis of the previous version of the skip-gram model based on hierarchical softmax, we can also summarize the skip-gram algorithm process based on negative sampling. The gradient iterative process uses random gradients to increase:
Input: text training sample based on skip-gram, mccunt, 2c context size of skip-gram, steps long, nog of negative sample。
Output: model parameters for each word in the glossary, all word vectors xw
1. Random initialization of all model parameters, all word vectorsw
For each training sample \\(co)Ntext (w 0), w 0), negative sampling of neg central words \ (w i, i=1,2, ... Eg\)
3. An iterative process of gradients for each sample of the training concentration ((co)Ntext (w 0), w 0, w1, ... W neg}\) does the following:

References:
Word2vec (iii) model based on negative sampling
Word2vec details the mathematical principles