Knowledge management is key not only to the simplicity of documentation and information, but also to the transformation of fragmented knowledge into team productivity. This paper will explore in depth the essence of knowledge management, analyse its importance in the product team and provide a systematic knowledge management framework and a guide to practice to help product managers build efficient knowledge management systems, increase team collaboration efficiency and promote business growth。
The day-to-day work of the product manager can be described as chicken flying dogs. Development students ask for details of their needs repeatedly, the operation does not find the most up-to-date location, the team's new interns can't get in the direction of their historical files, and the old people make one mistake... These problems that make their hair scratch, in essence, stem from the failure of knowledge management。
For a product team that relies on rapid decision-making and re-use of experience, knowledge is not water in sponges, but food in the kitchen — a wide variety of food items that can be easily dispersed, which can be confused without planning. However, building a science-based knowledge management system will make it possible to integrate fragmented needs, experiences and data into the knowledge engine that drives business growth. Today we come to talk about how best to manage knowledge and put your team back on track for efficient collaboration。
The essence of knowledge management: value transformation from data to experience
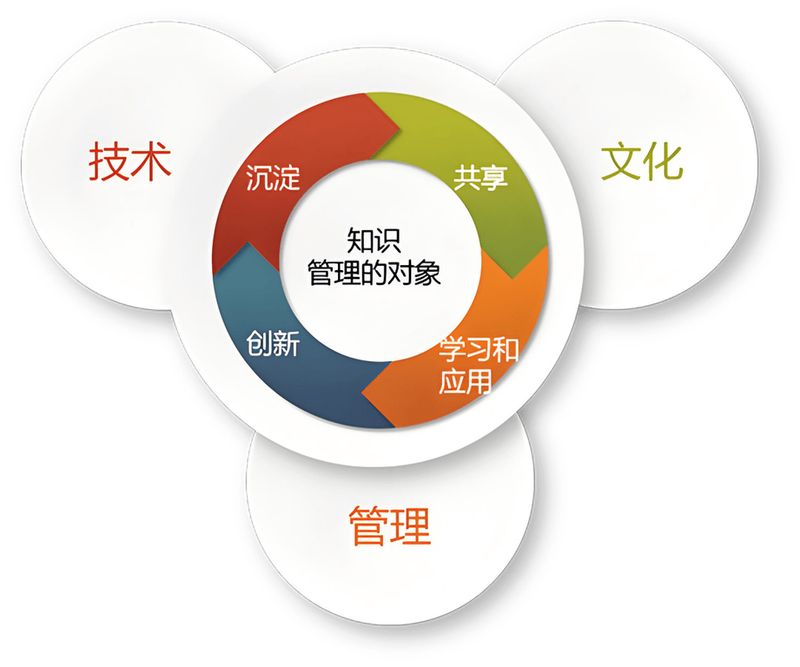
In short, knowledge management is the systematic operation of team knowledge assets. The “knowledge assets” here include not only well-written demand files, modeled technology programmes, but also ordinary meeting conclusions, client feedback and even the experience skills of older employees. At its core is knowledge-gathering organizations, knowledge-sharing and knowledge-overlaying, step by step, transforming debrisification information into reused, value-added experiences。
Give me a chestnut:
Core framework for efficient knowledge management
Good knowledge management is not the end of a warehouse, but the key is how knowledge can really be used and developed. In response, we can build an efficient knowledge management system around three core elements: capture, mobility, and iterative。
Knowledge-gathering: a web of information capture that is woven across the board
1) full-source data capture
In order to keep information from spreading, we need to access a variety of collaborative tools, such as flying books, micro-enterprises, business systems, such as crm, jira, and external resources, including industry reports, communities, etc. The automatic synchronization of structured data can be achieved through the api docking, and the unstructured data can be handled using cutting tools and voice-repeated techniques to ensure that the full chain information from the origin of the product to its final destination is effectively captured and deposited. The editing of impression notes allows for easy and quick collection of various types of information, such as web pages, documents and the like, and provides strong support for knowledge-gathering。
2) depth structured processing
The information initially collected is often fragmented and requires in-depth processing. The introduction of nlp technology to decipher fragmentation information, such as the extraction of client dialogue into standardized user portraits, pain description, functional advice, or the placement of “competing strategies”, “technology highlights”, “risk alerts” and these structured labels in industry reports. Identification and consolidation of duplicate content through semantic analysis to avoid knowledge redundancies. For example, we can group the content related to user privacy settings in different documents into a pool of knowledge that contains demand files, technical options, test examples。
3) asset classification management
Knowledge must be managed as an asset, and in common, knowledge is money. We can build a knowledge classification system based on business scenes, such as "product design" with "interactive specifications", "demand templates", "competence pool" and "development collaboration" with "interfacing document" "placement description" "technology programme library". Key attributes, such as business relevance, frequency updates, access rights, etc., are identified for each knowledge module, thus creating a clear, searchable and reusable catalogue of knowledge assets。
2. Knowledge flows: allowing knowledge to reach the right scene at the right time
1) build knowledge maps
Knowledge is not an island. We have built knowledge links along the business chain of demand, design, development, and operation, using product functionality as the core node. For example, under the payment module, we can link up its demand files, ui designs, interface files, client-action analysis reports, and iterative records, thus forming a complete knowledge chain of why, how and how. Following this map, employees can quickly find all relevant information and avoid finding needles in document piles。
2) smart referral system
It's still too inefficient for staff to search the required files. To make knowledge retrieval more transboundary, individualized recommended engines can be built based on employee roles (products/development/operation), current tasks (demand assessment/version planning/user research) and historical behaviour. When the product manager writes the new prd, the system automatically promotes historical programs for the same function, user pain tags, development of resource files, etc. When the developers screen the bug, the system automatically synchronizes the relevant interface change logs and test applications to turn knowledge into knowledge。
3) sceneation embedded
Knowledge acquisition is not detached from work, but rather integrated into the workflow, which allows for the integration of knowledge modules in depth in collaborative tools that staff use on a daily basis. For example, when the flying book discussion group refers to user retention rates, it automatically pops out historical operating programmes and data boards; when jira creates demand, the smart association imagines evaluation and risk scenarios for similar needs; and the figma design interface is embedded in an interactive specifications library shortcut to ensure seamless interface between knowledge acquisition and business operations。
3. The knowledge landscape: keeping knowledge and business up to date
1. Establishment of a mechanism for updating knowledge
It is worse than not. The product team can develop a clear knowledge update of the sop, setting up an updated rhythm by type: product demand documents are updated in a timely fashion after the version has been iteratively updated, site specifications are updated in line with the new functionality, competition analysis is fully updated before the quarterly surge. Particular attention was paid to using the version comparison tool to record each change, identifying who changed it, why。
2) periodic metabolic knowledge
Knowledge is always obsolete on the day it is phased out, assessing and marking low-value knowledge on the basis of reuse rates (the number of times quoted is low), freshness (the time of last update), relevance (the link to other knowledge is weak) and contributing to more efficient retrieval of the knowledge base. Key knowledge that is accessible to staff but is lagging behind can be linked to the smart referral system mentioned earlier, triggering automatic alert mechanisms to ensure that critical information is accurate at all times。
3) building a knowledge base for all staff
Knowledge is not a matter for a few, and it is necessary to break down barriers to knowledge sectorization and to open up co-creational competencies to engage front-line people in knowledge-building. The customer service can mark the focus point for the recent certification code in the user registration process document, develop additional technical realization details, and operate with actual impact data. Knowledge continues to grow and optimize in the common use and participation of the entire staff, through such functions as comment area discussions, version iterative records, etc., leading to knowledge management closed loops that raise questions, optimize programmes and validate results。
Iii. A guide to place-to-place knowledge management from framework to practice
In order to make the knowledge management system truly operational, there is a need not only for frameworks, but also for clear landing paths. This process could be broken down into five steps towards efficient knowledge management。
Current situational diagnosis: an in-depth study to map the “health levels” of knowledge management, with a view to finding the right point of pain: collecting through questionnaires the pains of staff in the knowledge acquisition, sedimentation, application, such as which scenes are most prone to information lags and which knowledge is needed but missing. Can we also see how many platform documents there are? How high is the repetition rate? Which documents are frequently accessed? These data locate the core issues. Using tools such as questionnaires, research can be initiated quickly and statistically analysed to inform the diagnosis of the current situation. Output diagnosis, problem identification: report of the findings. It is not enough to say no, but rather to specify problems and quantify impacts. For example, the needs assessment was delayed by two days because historical information was not available, and it took a week for newcomers to start working with their peers. This will allow us to see the value and space for improvement. Strategic planning: definition of a “blueprint” for a team knowledge base: knowledge is not a multiplicity, and classification management is required. Knowledge areas can be broken down by business scenes (e. G. Sales, r & d), type of knowledge (templates, cases, specifications), frequency of use (day-to-day vs occasionally checked), such as requirement templates for high frequency use, minutes of meetings, basic operating manuals; long-term user demand bank, product route planning documentation, competitive dynamic monitoring library. Setting priorities: with limited resources, we need to spread out. Short-term focus on high frequency pain points, such as fast-tracking product faq libraries, to improve the responsiveness of client services; long-term construction of strategic assets such as user demand gene banks to provide bottom support for product innovation. 3. Tool selection: good steel with blades let's go
The size of the team is different and the tools to choose are different。
4. Process re-engineering: moving knowledge alive
Input side: don't let knowledge get stuck in the first step. Key resolutions and to-dos can be submitted on a mobile phone within one hour of the meeting and task boards with responsible persons and deadlines are automatically generated. In the face of user complaints, the client service system automatically connects to the knowledge base, directly converts complaints into standardized knowledge cards and saves manual recording。
Output side: knowledge validation is embedded at key business nodes such as needs assessment, version planning, systems automatically generate knowledge readiness reports, check for historical similarity, competition dynamics or updates, and automatically link relevant technical documents and test standards to ensure quality of delivery when developing surveys。
Culture development: making knowledge-sharing a customary knowledge credit system: points are earned by uploading a good template, solving a high frequency problem and updating an outdated document. Accrual convertible training opportunities, funding for team activities or small incentives give value and value to the effort. Area integration: the induction training for new entrants must include the knowledge base and ensure that everyone can use it through small tests. The weekly meetings add a flash of knowledge, focus on the high-value experience deposited in operations and make knowledge-sharing a natural part of daily collaboration. Iv. Future trends in ai-driven knowledge management
The outbreak of generating ai and large model technologies is deeply reshaping the form of knowledge management. Knowledge management in the future will be smarter, more proactive and more pervasive。
It may be envisaged that ai can automatically generate the prd framework, interactive prototype reference, risk assessment checklist, etc., based on your needs description, significantly lowers the cost of preparing the underlying document. The addition of ai would also allow the system to predict high-frequency access to knowledge through historical data, such as the preparation of a repository of activities, including contingency plans, data indicators, client complaints processing, etc., before major advances. Even better, ai is able to integrate knowledge services into the tool chain, e. G., extracting interactive specifications in figma's design, popping points during sql queries, showing where there really is business and where there is knowledge services。
Concluding remarks
In sum, knowledge management, from disorderly data to orderly knowledge, to the knowledge engine that drives business growth, regardless of the size of the team, always depends on a good methodology, a suitable tool chain and a shared organizational culture. What are the knowledge management challenges facing your team? How did you solve it? Welcome to the comment section