
It's amazing! It's so easy to fish. Let's see what you don't know
Clinical data are growing at an exponential rate at a time when the tide of medical information is sweeping the globe. These data, which are scattered throughout the clinical process, are both “rich mines” for medical research and, due to different formats and the lack of standards, expose researchers to the “mineless” dilemma. The emergence of a pool of scientific expertise is providing a key programme for overcoming this challenge. How can it integrate multi-modular data and enable clinical research as the core infrastructure of the medical data age? What are the new possibilities for precision medical development? Together, we are looking into the current state and future direction of research and research expertise。
Building a scientific and research pool: dual drivers of policy and clinical
The research pool is not empty, but a corollary of policy orientation and clinical needs。
At the policy level, the national commission for health and health, in its national standards and standards for the information construction of hospitals (preliminary) explicitly states that the capacity for clinical research should be enhanced through the use of technologies such as big data and artificial intelligence. The long-standing problem of data fragmentation and uneven quality in traditional scientific models - the fact that one hospital has a different format for testing data than another and that unstructured texts in electronic medical records are difficult to access directly are severely slowing down the progress of research. Through standardized data governance, the specialized databases can “wrote together” scattered data to address the root causes of data use difficulties and become important practices in responding to national health information policies。
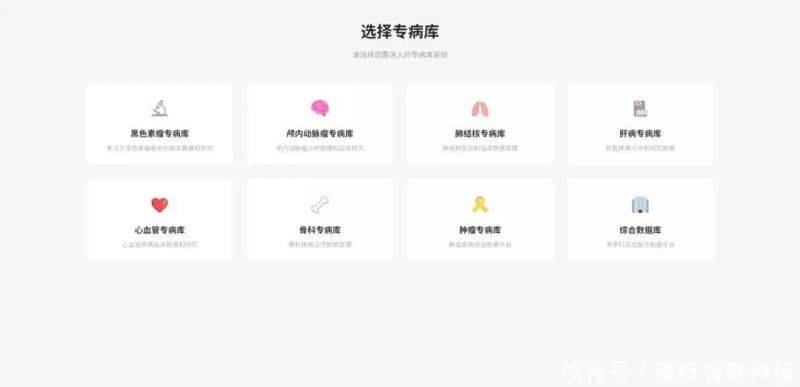
From a clinical point of view, specialized studies have very high levels of “deepness” and “widespread” of data. For example, oncological studies require not only clinical and inpatient records, but also full life-cycle information such as video reports, genetic sequencing data and long-term follow-up results. In the past, researchers have often spent a great deal of time collating data manually from different systems and even interrupted research because of incomplete data. With a disease-specific focus, the collection integrates multi-modular data, satisfying both the need for “specific data” in precision medical research and providing data support for individualized treatment programming, and radically changing the “supply-to-demand” situation of scientific data。
How does technology land? To discover the core of the research pool
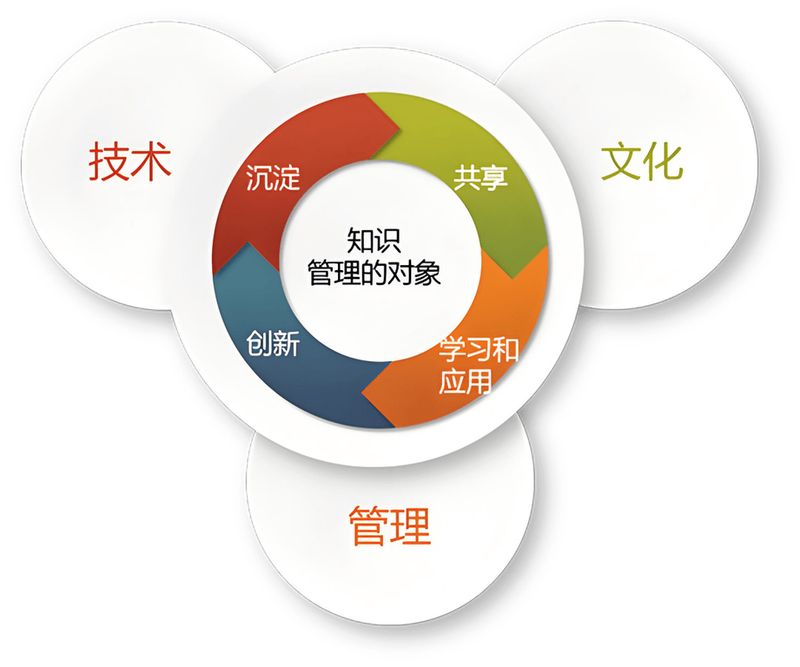
A well-functioning pool of scientific expertise is based on well-established technological structures and science-building strategies. In its participation in the project, shanghaito nuclear intelligence technology ltd. Is deeply aware that “data integration + quality control + efficient collection” is the three key elements for success。

New upgrade of the chinese version of the soybean version of ai
Multi-mode data integration: breaking the data “language barriers”
The data sources of specialized databases are extremely broad, ranging from structured data (e. G., testing indicators, drug records) to non-structured data (e. G., electronic medical records, video reports). In order to “connect” these data, we use the nlp technology to transform textual information from medical records into analytical structured data, while at the same time using knowledge mapping techniques to link diseases, symptoms and treatment programmes and construct standardized data systems。
Data governance and quality control: ai enabling, safeguarding data quality
Data quality is the “lifeline” of a specialized database. Using such criteria as ohdsi, which assesses the maturity of the data management capacity, we have established a process-wide data quality management mechanism: from metadata management (defining data sources, formats), to terminological harmonization (harmonization of diseases, drug names), to the construction of patient master indexes, diagnostic indexes, etc., to ensure that each data is “retroactive and verifiable”。
More importantly, we have introduced the ai large model to optimize mass controls - automatically calibrating the integrity of data through algorithms (e. G., whether key test values are missing), accuracy (e. G., whether age corresponds to disease history) and designing exclusive logical rules for medical scenes (e. G., whether post-operative drugs match the type of surgery). Not only did ai effectively reduce error rates compared to traditional manual controls, but it also significantly improved quality control efficiency and improved data quality。
Visualized collection system: saving time for data collection
Clinicians are core participants in data collection, but cumbersome operations often lead to low levels of participation. To this end, we have developed visual collection systems to address this problem in two ways:
(a) in-house data "automated": automatic collection of data in real time or t+n (e. G. T+1, updated the following day) using etl technology through interfacing with systems such as hospitals his, lis, etc., does not require manual entry
Out-of-house follow-up: design a self-defined form that allows doctors to adapt the collection field flexibly to the research needs, while reducing the time required for data collation to 10 minutes by using real-time synchronization technology. This optimization has led to a significant improvement in the efficiency of doctors ' work and to the safeguarding of the integrity of follow-up data。
What's the value of that
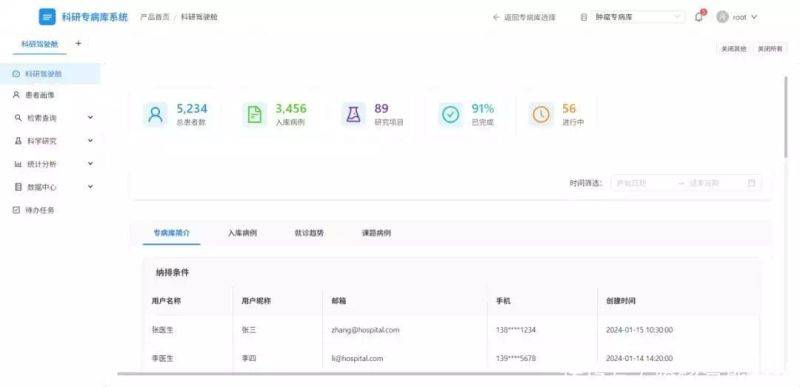
After many years of building practice, the application value of the specialized research database has been highlighted in a number of scenarios as a “accelerator” for the development of medicine。
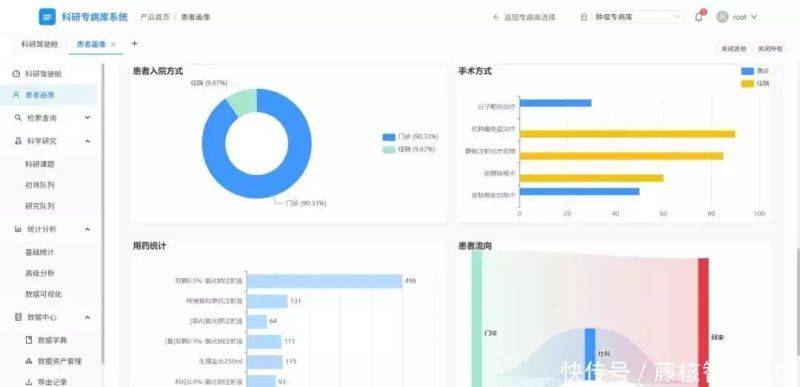
Improved scientific efficiency and accelerated transformation of results
In the past, when multi-centre studies were conducted, scientists had to check data on a hospital-by-hospital basis, and case screening alone could take months. The smart case-retrieving function of the specialist database allows rapid screening of eligible cases based on research needs, while supporting dynamic analysis – for example, a team study on “the efficacy of a drug for patients with lung cancer” – allows data on patients in different hospitals to be retrieved by the specialist database, and automatically analyzes indicators such as survival, adverse effects, etc., of the drug. In addition, it allows for the intellectual recruitment of patients, the provision of accurate groups of people tested for new drug development, clinical trials and the acceleration of scientific research from laboratory to clinical applications。
Supporting clinical decision-making and improving patient prognosis
Based on the volume of real world data accumulated by specialized banks, we can build disease prediction models, which are 90 per cent accurate. Based on model results, doctors can develop more intensive follow-up and individualized treatment programmes for high-risk patients, effectively reducing relapse rates and improving patient prognosis. This “data-driven” decision-making model makes clinical treatment more precise and scientific。
Promotion of scientific linkages to achieve “integrated clinical science”
The construction of a specialized medical repository has broken down the interdisciplinary “data barriers”. Diabetes collections, for example, not only integrate endocrine data, but also include data from relevant departments such as ophthalmology (diabetes retinal membranes), kidneys (diabetes kidneys). This interdisciplinary integration of data allows doctors to study diseases from a more comprehensive perspective and promotes the development of multidisciplinary collaboration (mdt) models, while allowing for rapid transformation of clinical problems into scientific research, which in turn feeds into clinical treatment and creates a virtuous cycle of “clinical-scientific” research。
Future period: the three main directions of the research pool
As technology continues to improve, the construction of a specialized research database will not stop at “data integration”, but will move in a more intelligent, open and normative direction。
Multi-centre collaboration + privacy calculations: secure shared data
Currently, most specialized databases are still limited to single hospitals or regions, with limited data size and coverage. The next generation of specialized medical banks will achieve data sharing across institutions and regions by means of privacy computing techniques (e. G. Federal studies, homogenous encryption), while safeguarding the privacy of patients. For example, the oncology bank in a hospital in beijing and the similar bank in a hospital in shanghai can jointly model the model without exchanging raw data, enhance the model's generalization capacity and allow multiple centres to study the real “discretionary”。
Smart upgrade: getting data “to speak”
The future specialized repository will no longer be "data warehouse", but "smart assistant." we plan to combine ai technology to build a dynamic knowledge base - to update, in real time, up-to-date national and international clinical guidelines, research results and links to the database; and to develop automated analytical tools, such as patient data uploaded by a doctor, that will automatically generate diagnostic advice, scientific assumptions, and even predict disease progress. This upgrade will move data from “passive call” to “active enabling”, significantly reducing the cost of scientific research and clinical work。
Standardization + ethical norms: building the foundations of development
Unharmonized data standards remain an important constraint on the development of specialized databases. In the future, we will promote the refinement of the data standards system, such as the unified use of icd-10 disease codes, loinc testing project codes, so that data from different specialized databases are “interoperable and comparable”. At the same time, an ethical data-use mechanism will be established to clarify the extent to which data are used and the process of authorizing them, to ensure that each data call complies with legal and ethical requirements and to safeguard the privacy and interests of patients。
A new future for precision medicine, with a special repository as the key
The construction of a specialized medical database is a crucial step in the transition from “quantity accumulation” to “mass leap”. It not only addresses difficulties in the use of clinical data, but also serves as a central link between clinical and scientific research and the promotion of precision medicine。
As an enterprise in the field of deep-tilled medical information, shanghai nuclear smart technology ltd. Has been working to enable medical development with technological innovation. We believe that, with the advent of technology such as the integration of multi-modular data, the upgrading of ai's intelligence and the sharing of safety across institutions, the specialized research database will provide stronger data support for the healthy china strategy, open new avenues for medical research and provide better quality medical care for patients。
In the future, we all look forward to a new chapter of precision medicine that will unlock the value of medical data